
DL常用操作
Leonhardt 2022-03-28 About 6 min
# Dataloader, Dataset和Sampler
先简单介绍一下Dataloader, Dataset和Sampler:
- Dataset即数据集,是实际数据存储的地方,可以简单的视为一个列表,列表中的元素为
(X, y) - Sampler用于产生索引
- Dataloader使用Sampler产生的索引逐批量的读取Dataset中的数据。通常我们就是在每个产生的小批量上进行预测,计算损失,准确率,执行梯度下降。
# 数据采样
torch.multinomial(input, num_samples, replacement=False) → LongTensor
- replacement=False时,为不放回抽样。replacement=True时,为有放回抽样。
- num_samples为需要抽样出的样本数。显然,replacement=False时,num_samples不能超过对应的输入元素个数。
- 当input为一维时,返回值为长为num_samples的一维张量。
- 当input为二维时,返回值为
input.shape[0]个num_samples长的二维张量。 - input的元素必须为float类型
- input的值的相对大小就代表了其索引被抽取的概率。可以理解为其内部会自动归一化。不要求input的值或其每一行的值总和为1,但其值必须非负,非inf,和大于零。
- 返回值为LongTensor,每个元素为抽取的样本在input相应行的索引值。
# Dataloader
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False)
- dataset, batch_size
- shuffle为False,使用SequentialSampler,为True则使用RandomSampler
- sampler可以自定义,但要注意此时不可有shuffle参数。
- batch_sampler作用是将sampler产生的索引列表根据batch_size分组。
- collate_fn作用是将一个batch的样本合并为一个张量。即
[(X1, y1), ....] ==> ([X1, ...], [y1, ...]) - pin_memory: //TODO
- drop_last表示当数据集中最后一点数据凑不够一个batch时,是直接丢弃,还是就将剩下的数据算作一个batch。
- num_workers表示使用多少线程加载数据。Windows上有bug,只能单线程。
Dataloader的核心代码
# 老版本
def __next__(self):
if self.num_workers == 0:
indices = next(self.sample_iter) # 用Sampler确定索引
batch = self.collate_fn([self.dataset[i] for i in indices]) # 从Dataset获取每个数据后合并
if self.pin_memory:
batch = _utils.pin_memory.pin_memory_batch(batch)
return batch
# 新版本 更复杂了,但基本逻辑还是一样
def __next__(self) -> Any:
...
data = self._next_data()
...
def _next_data(self): # 位于_SingleProcessDataLoaderIter下
index = self._next_index() # may raise StopIteration
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
if self._pin_memory:
data = _utils.pin_memory.pin_memory(data)
return data
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# Sampler
Sampler的核心方法是__iter__
- RandomSampler: shuffle为True时,replacement为False。
- data_source: 数据集
- num_samples: 指定采样的数量,默认是所有。
- replacement: 默认为False,使用
randperm(n)。若为True,则表示可以重复采样,使用randint(n)。
- SubsetRandomSampler: 用于划分训练集和测试集
- indices: 直接传入需要的索引。在迭代时顺序会被打乱
(self.indices[i] for i in torch.randperm(len(self.indices))
- indices: 直接传入需要的索引。在迭代时顺序会被打乱
- WeightedRandomSampler: 加权采样,用于处理类别不平衡问题。
- weights: 权重张量。相对更大的值代表的索引更容易被选中。
- num_samples: 指定采样的数量
- replacement: 默认为False,使用
randperm(n)。若为True,则表示可以重复采样,使用randint(n)。
SubsetRandomSampler使用示例
n_train = len(train_dataset)
split = n_train // 3
indices = list(range(n_train))
random.shuffle(indices)
train_sampler = torch.utils.data.sampler.SubsetRandomSampler(indices[split:])
valid_sampler = torch.utils.data.sampler.SubsetRandomSampler(indices[:split])
train_loader = DataLoader(..., sampler=train_sampler, ...)
valid_loader = DataLoader(..., sampler=valid_sampler, ...)
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
WeightedRandomSampler使用示例
# 有4类,样本数分别为
class_counts = [10, 20, 30, 40]
class_weights = [1/c for c in class_counts]
sampler_weights = [] # 计算每一个样本被采样到的概率
for w, c in zip(class_weights, class_counts):
sampler_weights += [w] * c
# 归一化后,更好理解sampler_weights的每一个值,代表一个样本被采样到的概率。
# sampler_weights = [x/sum(sampler_weights) for x in sampler_weights]
sampler = torch.utils.data.sampler.WeightedRandomSampler(sampler_weights, num_samples=len(sampler_weights), replacement=True)
loader = DataLoader(..., sampler=sampler, ...)
1
2
3
4
5
6
7
8
9
10
2
3
4
5
6
7
8
9
10
BatchSampler: 将sampler产生的索引列表根据batch_size分组
def __iter__(self) -> Iterator[List[int]]:
batch = []
for idx in self.sampler:
batch.append(idx)
if len(batch) == self.batch_size:
yield batch
batch = []
if len(batch) > 0 and not self.drop_last:
yield batch
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
# 另一种数据集划分方法random_split
torch.utils.data.random_split(dataset, lengths)
- dataset 要划分的数据集
- lengths 需要划分出的数据集的长度列表
random_split(range(10), [3, 7])
1
# 范数与标准化
# scipy随机变量
scipy的stats模块中整合了大量连续分布和离散分布的随机变量对象(RVs)。连续分布的RV包含以下方法
- rvs: Random Variates
- pdf: Probability Density Function
- cdf: Cumulative Distribution Function
- sf: Survival Function (1-CDF)
- ppf: Percent Point Function (Inverse of CDF)
- isf: Inverse Survival Function (Inverse of SF)
- stats: Return mean, variance, (Fisher’s) skew, or (Fisher’s) kurtosis
- moment: non-central moments of the distribution
- 这些方法都有默认的关键词参数loc=mean, scale=std。norm默认为标准正态分布。
from scipy import stats
# pdf和cdf就是统计中的概率密度函数和累积密度函数
# RV的方法都可以输入一个向量,返回一个每个元素都用相应函数处理过的向量。
# 以正态分布为例
stats.norm.pdf(0) # 0.3989
stats.norm.cdf(0) # 0.5
stats.norm.cdf([-1.0, 0, 1.0]) # array([0.15865525, 0.5, 0.84134475])
stats.norm.mean()
stats.norm.std()
stats.norm.var()
stats.norm.stats(moments="mvsk") # 返回均值,方差,偏度系数,峰度系数
# ppf是cdf的反函数。percent = cdf(x) ==> x = ppf(percent)
stats.norm.ppf(0.5)
norm.rvs(size=3) # 从正态分布中产生3个随机数
# 冻结分布 Freezing Distribution
norm_rv = stats.norm(loc=5, scale=2) # norm_rv和stats.norm用法相同,但默认参数不同
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 截断分布-scipy.stats.truncnorm
将标准正态分布截断到[a, b]
移动和缩放分布:truncnorm.pdf(x, a, b, loc, scale) 等价于 truncnorm.pdf(y, a, b) / scale,其中 y = (x - loc) / scale
要想将自定参数的正态分布截断到指定[ma,mb],则需要重新计算形状参数 a, b = (ma - mean)/std, (mb - mean)/std。
mean, std = 2, 4
ma, mb = 0, 4
a, b = (ma - mean)/std, (mb - mean)/std
x = np.linspace(-5, 5, num=1000)
pdf = stats.truncnorm.pdf(x, a, b, mean, std) # 下图一
# pdf = stats.truncnorm.pdf(x, a, b) # 下图二
fig = sns.lineplot(x=x, y=pdf)
1
2
3
4
5
6
7
2
3
4
5
6
7
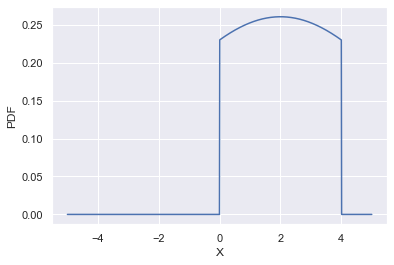
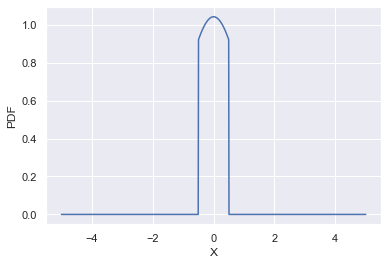
# 谱归一化
SNGAN (opens new window): 在GAN的Discriminator中使用,标准化Discriminator的权重参数,使其满足1-Lipschitz约束。