
ConvNeXt
Leonhardt 2022-01-17 About 2 min
# 摘要
2020年以来,在视觉识别领域,Vision Transformers(ViTs)迅速超越了ConvNets成为当前最好的模型。纯ViT在图像分类上表现很好,但泛化到检测,分割任务时遇到了困难。hierarchical Transformer(e.g. SwinTransformer)通过重新引入一些卷积层解决了这个困难,在各种视觉任务中都表现良好。这种混合模型的优秀性能主要来自Transformer内在的优越性,而不是ConvNet。
这篇文章的工作是重新审视ConvNet的设计空间,探索纯ConvNet的极限。具体方式是,从ResNet50开始,逐步向ViT的设计看齐,从中发现提高性能的关键组分。其结果产生了一族纯ConvNet模型,称为ConvNeXt。性能堪比SwinTransformer,且保持了ConvNet的简单,高效。
# 主要内容
关键问题:Transformer的设计决策如何影响ConvNet的表现。
准备:用ViT使用的训练技巧来训练ResNet50(比原始的ResNet50表现更好),作为baseline。
训练技巧:确定后保持不变
- 300epoch
- AdamW Optimizer
- DataAugmentation
- Mixup
- Cutmix
- RandAugment
- RandomErasing
- 正则化
- Stochastic Depth
- LabelSmoothing
# 宏观设计(Macro Design)
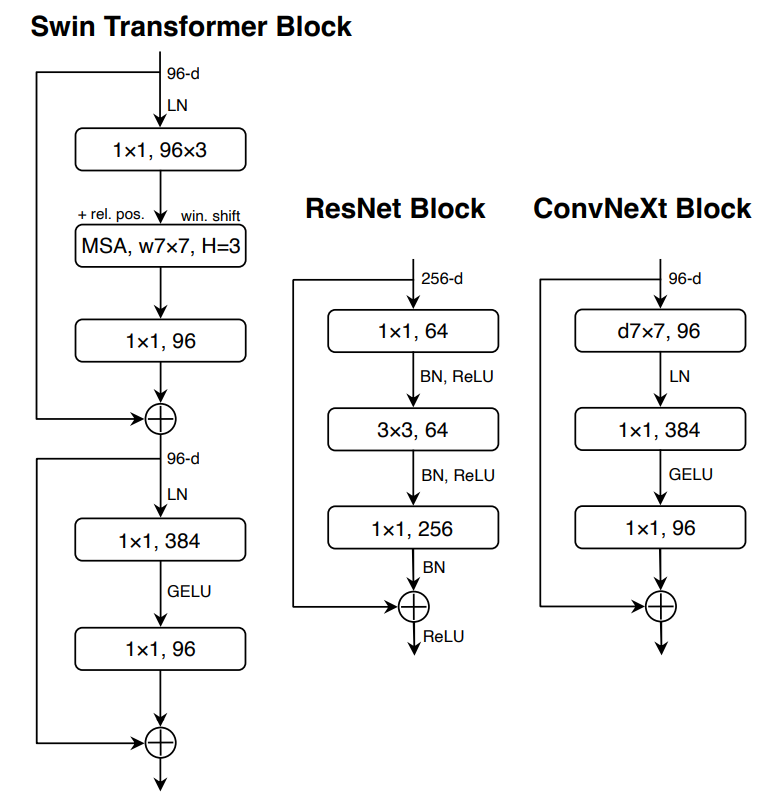
- change stage ratio:每一个stage的block数量比例(3:4:6:3)->(3:3:9:s3) +0.6%
- change stem cell: 比较激进的将输入图片下采样到合适的大小的初始卷积模块。(7x7conv,stride=2+max_pooling,stride=2)->(4x4conb,stride=4,称为patchify) +0.1%
- 使用ResNext提出的设计原则:"use more groups, expand width" +1%
- depthwise convolution groups=channels
- expand width 增加通道数到和SwinTransformer一样。64->96
- inverted bottleneck: 类似MLP,隐藏层神经元数量是输入层的4倍。bottleneck原来是用1x1卷积来降低通道数,现在反过来,用1x1卷积增加通道数。(总计算量实际还减少了?) +0.1%
- moving up deepwise conv layer:把depthwise convolution提高1x1卷积之前,类似ViT的MSA块在MLP之前。准确率降低了。但这是为后面增大核的效果做准备。
- increasing the kernel size to 7x7:增加核的大小,到7就基本饱和。虽然两个3x3卷积感受野大小和一个5x5卷积相同,但仍代替不了5x5的卷积,可能因为两个3x3的卷积重叠部分比较多,对一些特殊模式识别结果不如一个5x5的卷积。+0.7%
# 微观设计(Micro Design)
- ReLU->GELU:GELU很多好的模型在用,这里可以用GELU来替换ReLU,实验显示对性能没有影响。+0%
- 减少激活函数的使用次数:只在两次1x1卷积之间使用一次。+0.7%
- 减少标准化层 +0.1%
- BN->LN +0.1%
- 独立的下采样层:用2x2conv,stride=2来下采样。只加这种下采样会导致结果不能收敛。需要在每个下采样层前,stem cell后,最终的全局平均池化后添加LN层来稳定数值。 +0.5%