
语义分割
2021-12-13 About 9 min
# 什么是语义分割
- 将图像划分为不同意义区域的图像处理技巧
- 定义图像中不同语义实体边界的过程
- 根据视觉或语义特征将为每个像素做标注的过程
# 定义良好的分割问题
- 语义分割:每一个像素的类别属于事先定义好的一组类别。每一个语义实体的所有像素都属于同一类别。语义不仅由数据定义,问题也会影响语义。例如:行人检测中整个人属于一个语义实体,而动作检测中不同的部位属于不同的语义实体。显著目标检测:将场景中最重要的物体分割出来。前景背景分割。
- 实例分割:在场景中检测并分割同一类物体的多个实例,通常会伴有目标检测。
- 时域分割:不仅要在空间上做分割,也需要在时域上做处理。例如:物体跟踪,交通分析/监测。
- 低语义级分割:在低语义级别分割。例如:颜色,纹理的分割。常用方法为 over-segmentation + region merge。
- 有交互辅助的分割:有些分割算法需要和人做一些交互。一点点交互,就能大大提高分割质量。适用于复杂场景或训练数据不足的情况
# CNN系列分割算法
在Visualizing and understanding convolutional networks论文中,提出了CNN的卷积核倾向于生成物体特征的激活映射这一观点。激活映射可被看做物体特定特征的分割掩码。也就是说,CNN的结果就包含了分割需求的关键。 大多分割算法就利用了这一性质来产生解决问题所需的分割掩码。
通常认为,CNN中靠前的层,可以提取局部特征/细节信息。如等高线contours,物体的一小部分。且比较清晰(sharper)。而CNN中靠后的层,可以提取全局特征/粗糙边界。如可以分割出地面,天空,人类。但比较模糊(图片尺寸减小了)。如下图所示。

# FCN
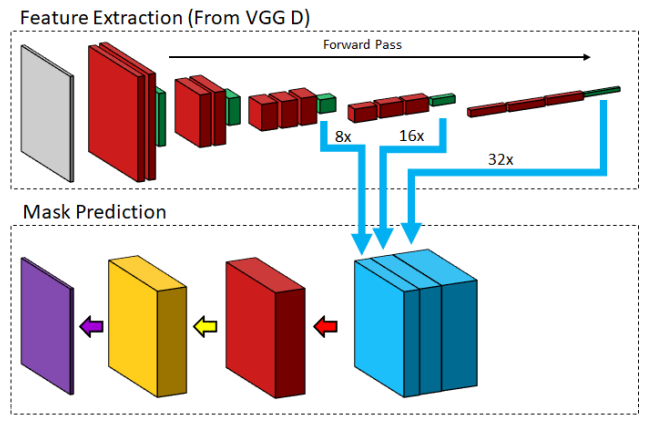
用于分类的CNN最后通常会将特征图展平,再通过全连接层,最后输出类别的概率分布。这会丢失图像的空间信息。
- FCN直接用最后的卷积块的输出来做像素级分类。这个卷积块是通过concat三个不同尺寸的特征图的上采样结果,经过一个卷积层融合特征后,在每个像素的通道维上用softmax函数处理,最后用argmax得到最终的分割结果。
- 另一种方案是使用全局平均池化(GAP)。即将n通道的特征图平均池化为n维向量,可以在很多训练好的模型(原来使用全连接层的)上使用,并将模型用于像素级分割任务。
CNN提取特征时,会经过几个下采样层,使特征图尺寸变小
- 好处:特征图的每个像素的感受野会变大
- 缺点:上采样的时候会丢失清晰度(一些细节信息)
FCN通过混合三个不同尺寸的特征图的上采样结果,得到更清晰的激活映射。此外,在FCN中,使用高维的核来捕捉全局信息也能改善分割结果。
# DeepMask & SharpMask
有两个分支,共享卷积层提取的特征
- 一个分支输出像素级类别概率
- 另一个分支为识别准确度打分
如图所示
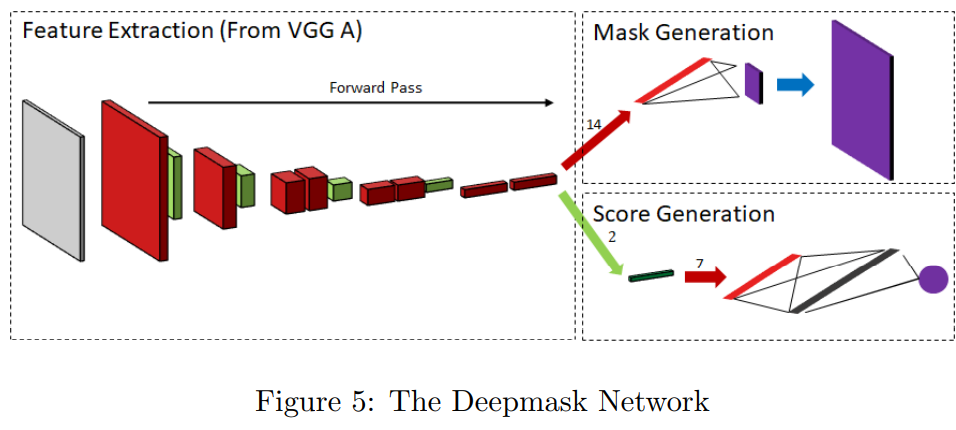
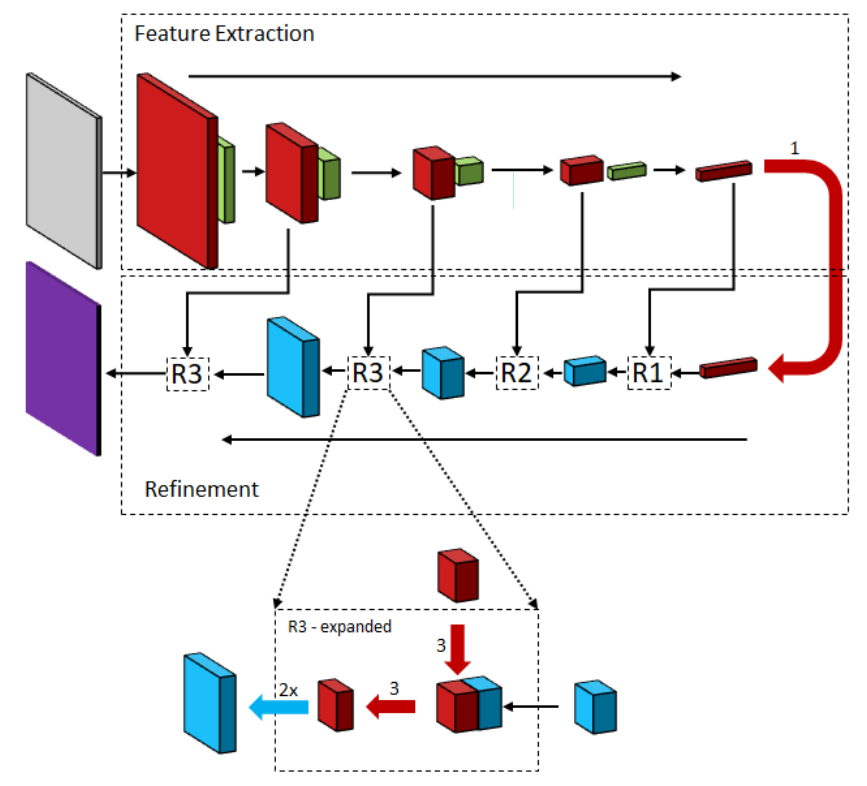
SharpMask提出了convolutional refinements,即将相同尺寸的CNN特征和上采样特征在通道维合并,在经过3x3卷积层融合后,再上采样得到下一层。如图所示
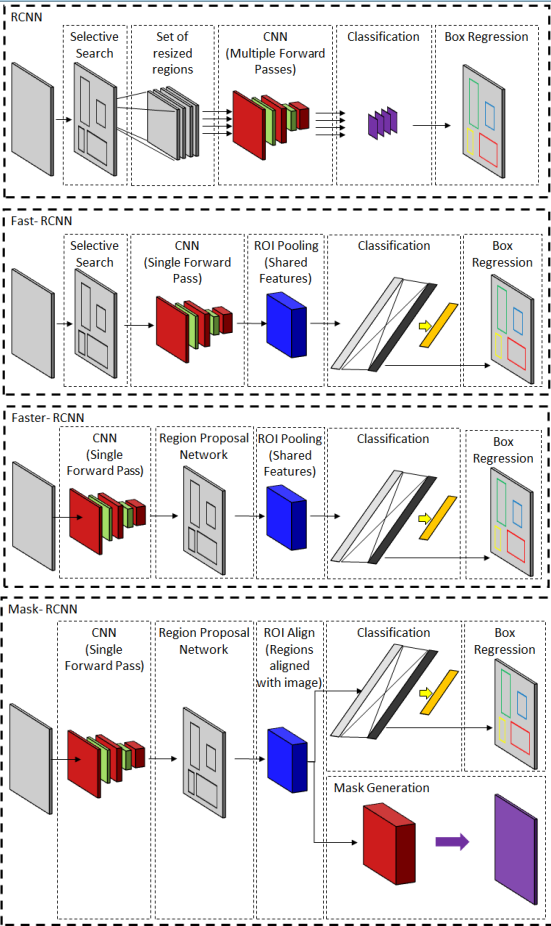
# RCNN系列
RPN通常被实例分割算法采用。定位物体实例后,再在目标区域做分割。
# DeepLab
对于像素级分割,使用小的3x3卷积核很难捕捉到上下文信息。
- 分类器中通常使用最大值池化增大感受野来解决这个问题,但这会导致清晰度下降,不利于分割。
- 使用大核,需要训练的参数量又会大大提升。
DeepLab的提出了三种方法来解决该问题:
# atrous/dialated convolution 膨胀卷积
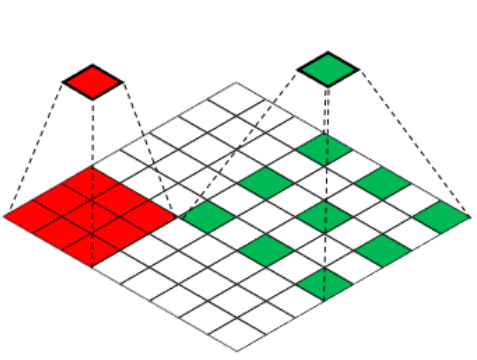
在核中间padding
# spatial pooling pyramid 空间池化金字塔
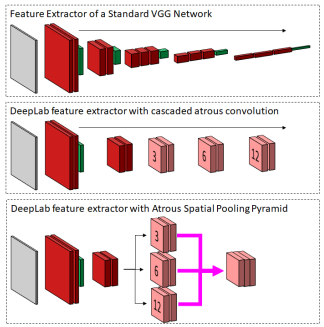
TODO
# fully connected conditional random field(CRF) 全连接条件随机场
CRF通常用于序列学习问题,而图像分割可以看做序列像素分类问题。
CRF属于概率图模型,以能量函数为特征。能量函数主要包含两项,一元势能项,即深度网络的输出,对图像有一个粗糙的划分;二元势能项,负责长程依赖,CRF中用成对势能表示。最初是作为后处理模块,后来其中关键步骤被一个循环的卷积流程替代了
CRF主要流程如下
- 初始化:在一元势能上使用softmax函数
- 信息传递(Message Passing):用两个高斯核(spatial+bilateral)卷积。用permutohedral lattice算法加速。
- Weighting filter outputs:用需要通道数的1x1卷积,对filter输出进行加权与求和
- Compatibility Transform:用Compatibility Transform跟踪不同标签的不确定性。用输入输出通道相同的1x1的卷积来模拟
- 添加一元势能项:用一元势能减去Compatibility Transform
- 标准化:另一个softmax函数
high-order dependencies:另一种端到端的网络使用高阶势能。用一系列特殊的卷积和池化操作提升普通VGG-like网络产生的像素级预测。
主要步骤:
- 局部卷积:在特征图的不同位置使用不共享的卷积核
- 类似CRF中的spatial卷积产生一个概率惩罚映射
- block min pooling:在每个像素的通道维上进行最小池化
# 使用多尺度特征预测
自然场景中的物体大小是不可知的,会受到个体差异,视角,远近等影响。
# PSPNet
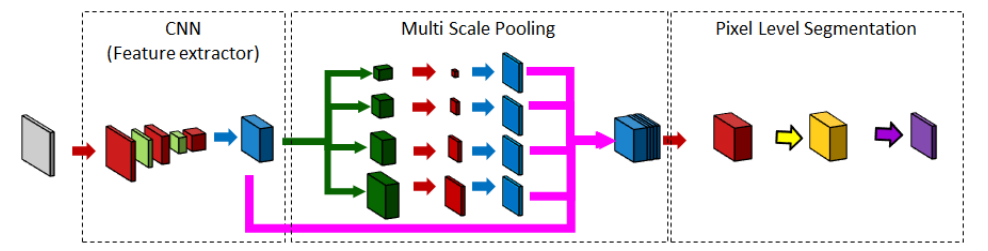
- 将ResNet101特征图上采样到输入大小
- 用1x1,2x2,3x3,6x6的平均池化得到不同尺寸的特征图
- 各个尺寸的特征图,经过卷积后,再上采样到原输入尺寸
- 将原特征图和先池化再上采样得到的特征图在通道维连接在一起
- 卷积,softmax,(argmax)得到预测结果
# RefineNet
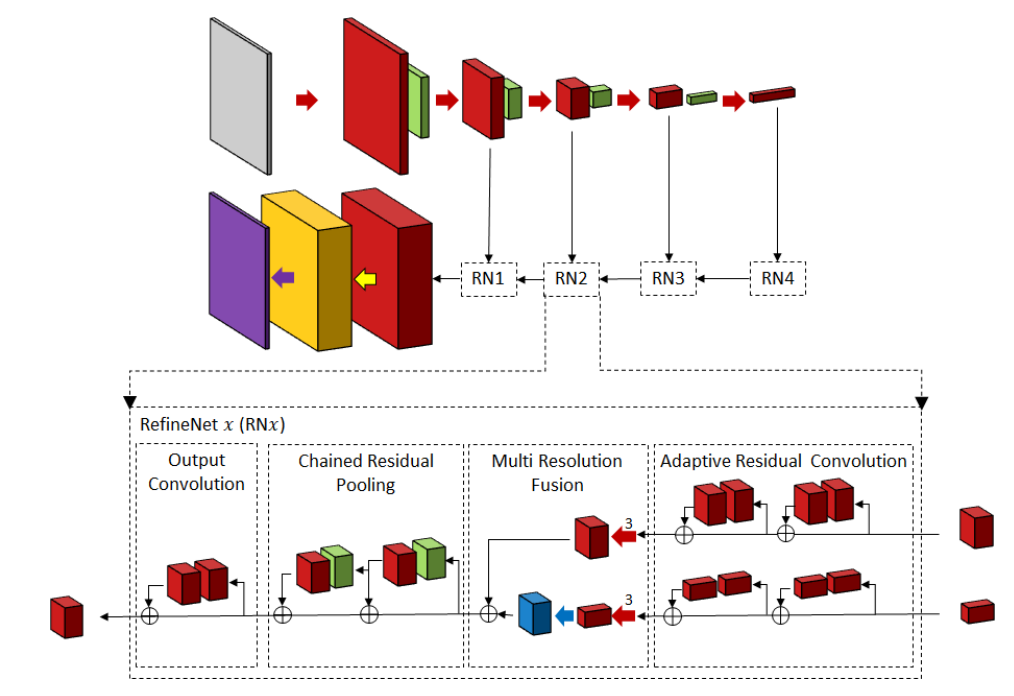
- RCU:为分割问题fine-tune过的卷积层
- MRF:合并不同分辨率的特征图,得到更好的特征图
- CRP:用不同尺寸的核池化(不改变特征图大小),以捕捉更大区域的背景上下文
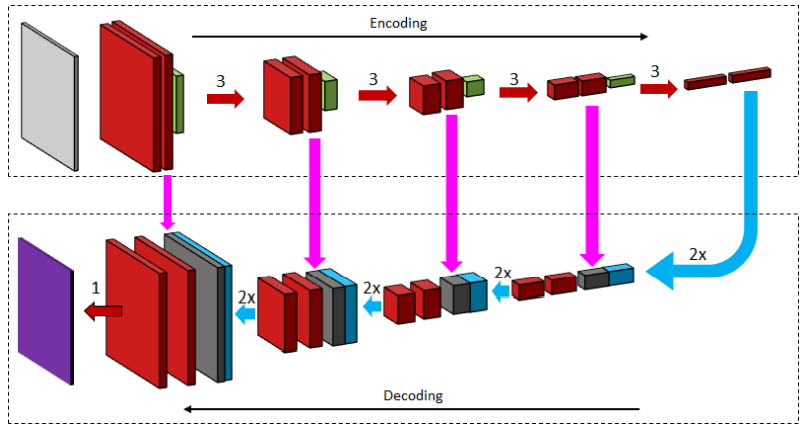
# AutoEncoder
最初是用于特征提取,并希望特征能尽可能保留原始图像信息。
AutoEncoder的组成
- encoder:将原始输入编码成尽可能低维度的中间表示。在CNN中,通常就是一系列卷积,池化或步幅为2的卷积。
- decoder:试图将中间表示还原为原始输入。这部分通常需要修改,以用于图像分割任务。在CNN中,比较tricky。包括:
- 转置卷积:也称deconvolution,先将特征图膨胀,然后再卷积。作为对比,atrous卷积,是将核膨胀,再卷积。
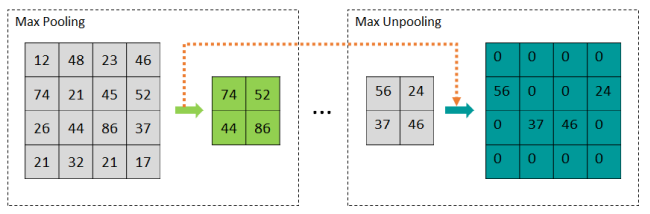
- 反池化(unpooling):将一个像素解压为2x2个像素,将图的宽高加倍。
- loss的计算:原始输入和还原结果的差距。在分割任务中是希望的像素分类分布和decoder产生的像素分类分布。
这类生成方法可以以更小的代价得到更清晰的边界,并且可以自由选择输入尺寸,结果总是输出一个和输入相同尺寸的输出。其主要的问题是:如何阻止encoder对图像过度抽象。
多尺度特征+AutoEncoder的组合在分割领域已经十分普遍了
# UNet
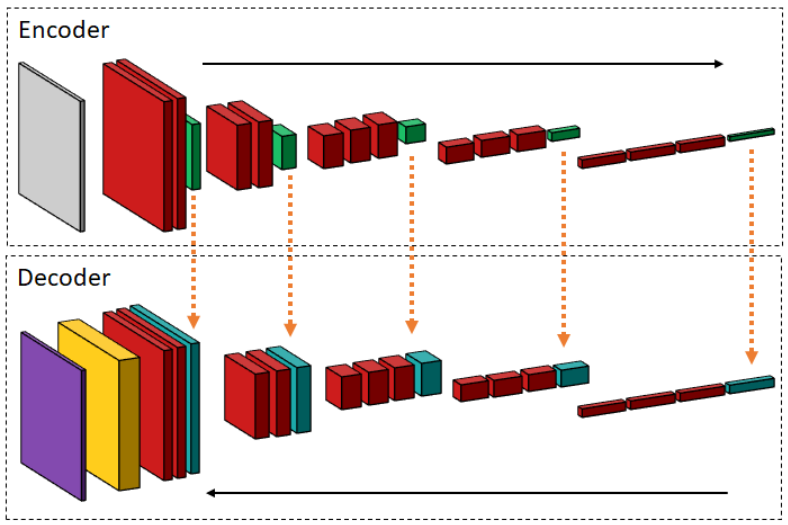
使用skip connection,将encoder和decoder对应的层融合。为了考虑到各种不同的抽象层次,将未压缩的激活映射直接复制到decoder对应的部分。
# SegNet
主要引入了forward pooling indices,即下池化时记录最大值位置,上池化时使用。避免在边界区域出现分类不一致。
# GANs
- 分割网络作为Generator
- Discriminator来分辨一系列masks是真值还是Generator生成的值
# 序列模型--用于实例级别分割
# Convolutional LSTM
作为Image Segmentor的suffix,可以在不同的时间步选择不同的物体实例。
# Attention
- 对定位独立的物体实例有更多控制
- spatial inhibition:学习一个偏移参数,即前面的分割结果和未来的分割结果之间的偏移
# 一个实例分割网络
- external memory:提供前一步物体边界细节信息
- a box network:预测下一个物体实例,输出一个图像的子区域
- segmentation module
- score:基于分割是否正确分割了物体实例为此分割打分
- 当分数低于用户预设阈值时,网络终止
# Interactive Segmentation
在场景太复杂,图像噪音太大或光照条件差等场景中,使用一点点来自用户的指导就能很大程度上提高分割的质量。
# Two stream fusion
有两个平行的分支,一个是普通的图像分割分支,另一个是代表用户交互的图像的分支,用两个分支的结果来得到更好的预测。
# Deep Extreme Cut
需要用户输入4个点,即物体的最左右上下四个点。通过从这些点创建的热图(heatmap),一个4通道输入被送入 DenseNet101 网络中。
# Polygon-RNN
从典型 VGG 网络的不同层中提取多尺度特征,并串联起来为循环网络创建特征块。RNN 则提供一系列表示对象轮廓的点作为输出。该系统是作为交互式图像注释工具而设计的。用户可以通过两种不同的方式进行交互。首先,用户必须为感兴趣的对象提供一个紧的边界框。其次,在构建了对象轮廓多边形之后,允许用户编辑多边形中的任何点。
# 构建更高效的网络
# ENet
- 不再使用对称的encoder和decoder,而让decoder浅一点。
- 在池化时不加倍通道数,而使用两个平行的池化操作
- 使用PReLU。(类似LeakyReLU,但小于0部分的斜率是可学习的参数)
# Deep Layer Cascade
TODO
# SegFast
- depth-wise separable
- depthwise separable transposed convolutions for decoding
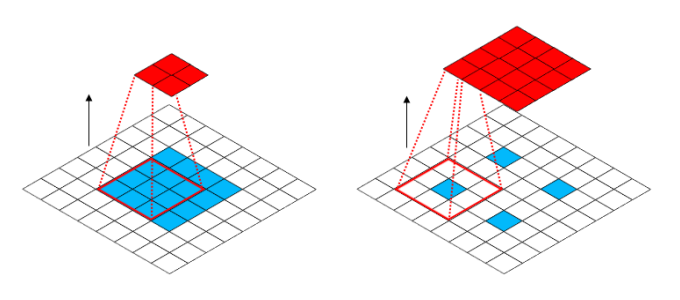
# Segmentation using superpixels
superpixels: 就是把一幅像素级(pixel-level)的图,划分成区域级(district-level)的图,是对基本信息元素进行的抽象。如图。
