StyleGAN
Leonhardt 2022-04-10 About 2 min
# StyleGAN v1
# 摘要
The new architecture leads to an automatically learned, unsupervised separation of high-level attributes (e.g., pose and identity when trained on human faces) and stochastic variation in the generated images (e.g., freckles, hair), and it enables intuitive, scale-specific control of the synthesis. The new generator improves the state-of-the-art in terms of traditional distribution quality metrics, leads to demonstrably better interpolation properties, and also better disentangles the latent factors of variation. To quantify interpolation quality and disentanglement, we propose two new, automated methods that are applicable to any generator architecture. Finally, we introduce a new, highly varied and high-quality dataset of human faces.
# 图
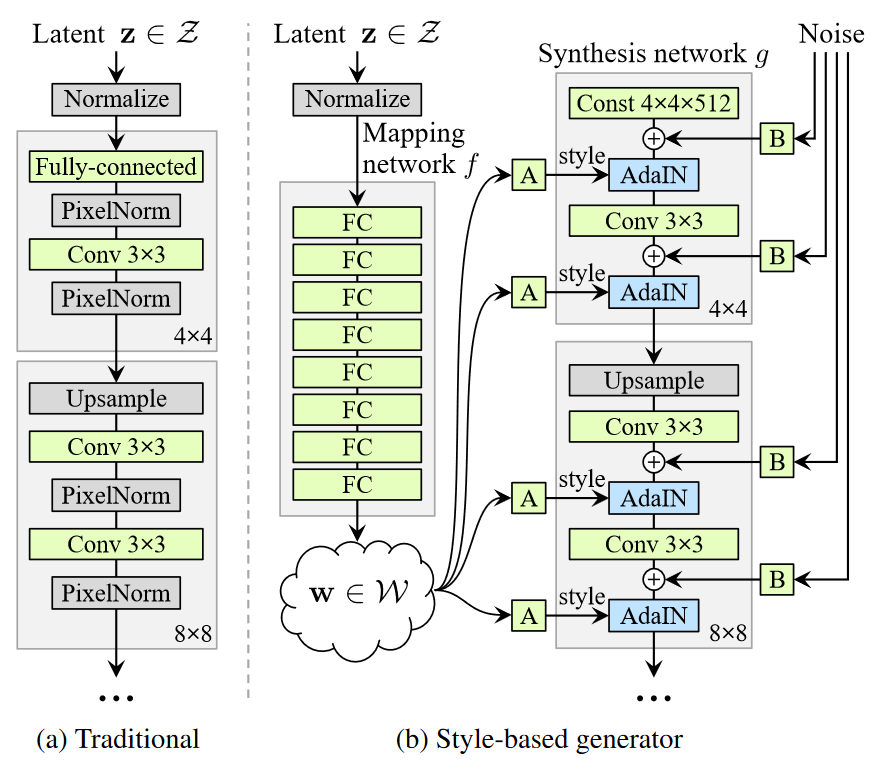
# 要点
- MappingNetwork: 8层FC,z->w,Disentangle
- AdaIN, Style w->ys,yb
- G的初始层使用学到的参数,而非和w相关
- 在每个卷积层后,AdaIN前加入高斯噪音图像。并且每个通道各有一个可学习的缩放因子用于控制噪音
- style mixing 选择一定比例的图像,在生成过程中随机选取某层,在该层后换掉原来的w,使用一个新的w'.一种正则技巧,不要让G觉得毗邻的style有关联
- style影响全局的属性,如姿势,脸型等,noise影响更细节的地方。这和风格迁移领域的结论一致,即:
空间不变的统计量(Gram矩阵,每通道像素的均值,方差等)编码了图片的style,随空间变化的特征编码了特定的实例 - Perceptual path length:用于量化隐空间的缠结程度。具体而言,用在隐空间插值生成的图像的变化程度来衡量。$ \begin{array} { l } { l _ { z } = E [ \frac { 1 } { \epsilon ^ { 2 } } d ( G ( slerp ( z _ { 1 } , z _ { 2 } ; t ) ) _ { 1 } ) } ,{ G ( slerp ( z _ { 1 } , z _ { 2 } ; t + \epsilon ) ) ) ] } \end{array} s.t. \space t \in [0, 1],\epsilon=1e-4 \begin{array} { l } { l _ { w } = E [ \frac { 1 } { \epsilon ^ { 2 } } d ( G ( lerp ( z _ { 1 } , z _ { 2 } ; t ) ) _ { 1 } ) } ,{ G ( lerp ( z _ { 1 } , z _ { 2 } ; t + \epsilon ) ) ) ] } \end{array} s.t. \space t \in [0, 1],\epsilon=1e-4$
- 线性可分性: 为每个属性训练一个二分类SVM,然后计算条件熵H(Y|X),值越小越好。#TODO
# StyleGANv2
# 摘要
redesign the generator normalization
revisit progressive growing, and regularize the generator to encourage good conditioning in the mapping from latent codes to images.
identify a capacity problem
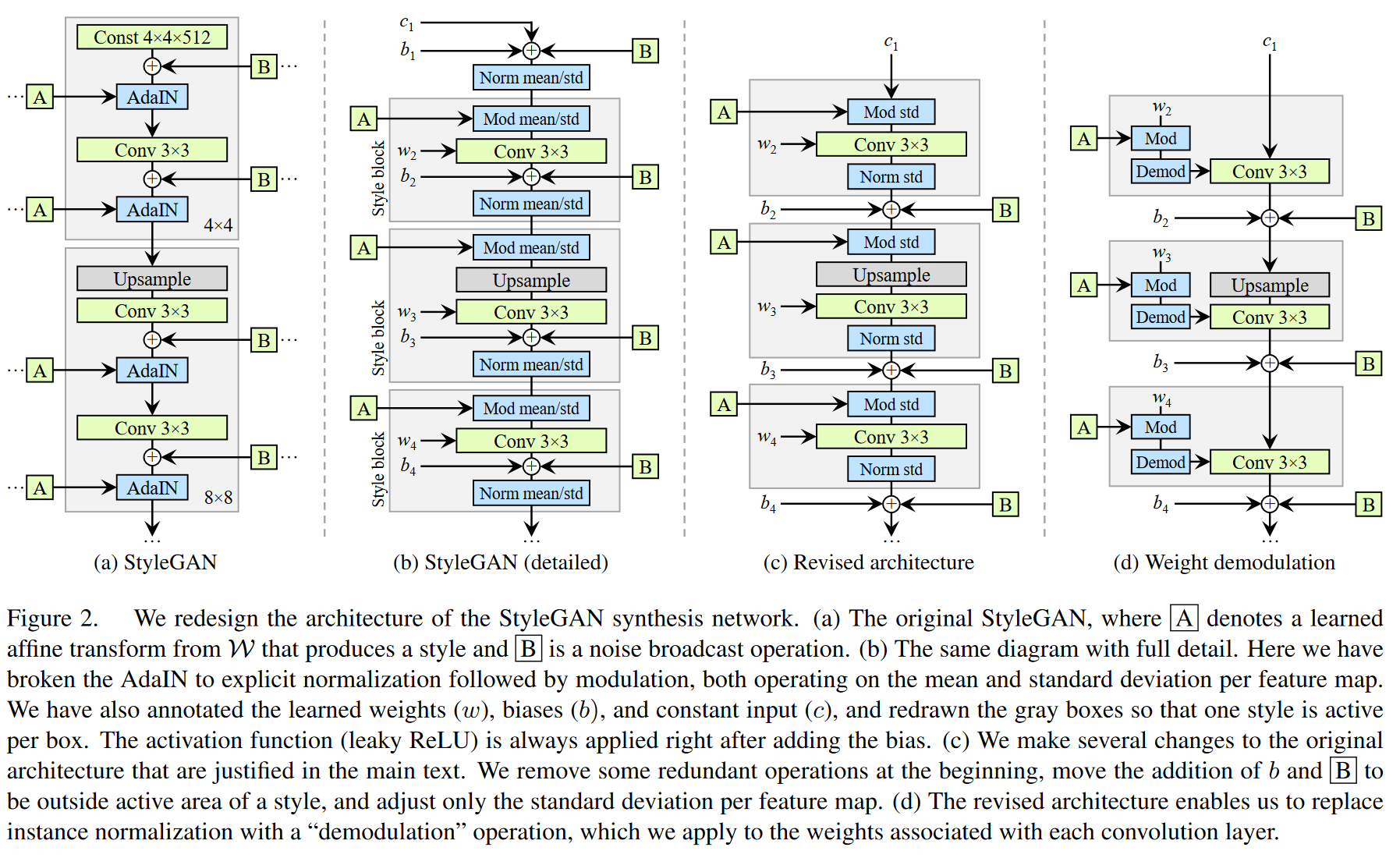
# 图