经典网络的要点
Leonhardt 2022-01-18 About 2 min
# DenseNet
- 在每一个block内,每一层特征图的输入都包含前面所有层的特征图,其输出也会传递到后续所有层的输入中。
- 不像ResNet一样,特征图是通过逐元素相加合并的。DenseNet的处理方式是将所有输入拼接起来。
- DenseNet的参数更少,计算效率更高。原因是其架构允许其输出较窄的特征图(每一层的输出通道数k可以很小,如k=12)。
- 为什么有效
- CNN的特征图可能包含两部分,一部分用于保存来自前面层的关键特征,一部分用于产生新的特征。ResNet等CNN架构的特征传递是逐层传递的,保存的特征逐层增加且都要复制到下一层,效率较低。DenseNet直接将每一层的特征都传入后续所有层,因此,每一层只需要计算新的特征即可,需要保存的特征可以重用之前的计算结果,因此DenseNet的特征图可以很窄,且计算效率更高。
- DenseNet每一层都连接到最后的输出,即和loss函数直接相连,相当于一个隐式的Deep Supervision?
# MobileNet
提出了Deepwise Separable Convolution。降低参数数量和计算复杂度的同时,性能略有下降。让网络更轻量化。
- 标准的卷积的作用通常为用卷积核提取特征,并同时将提取出的特征融合生成新的表示。
- Deepwise Separable Convolution,深度可分离卷积将特征提取和特征融合两个步骤分开,先用一个deepwise的卷积提取特征,再用1x1的卷积融合特征。
- Deepwise convolution:就是输入的每个通道使用一个独立的核来计算。不像标准卷积,每个核能看到所有的输入通道。
- pytorch实现deepwise卷积:nn.Conv2D(c_in, c_out, kernel_size=3, groups=c_in)
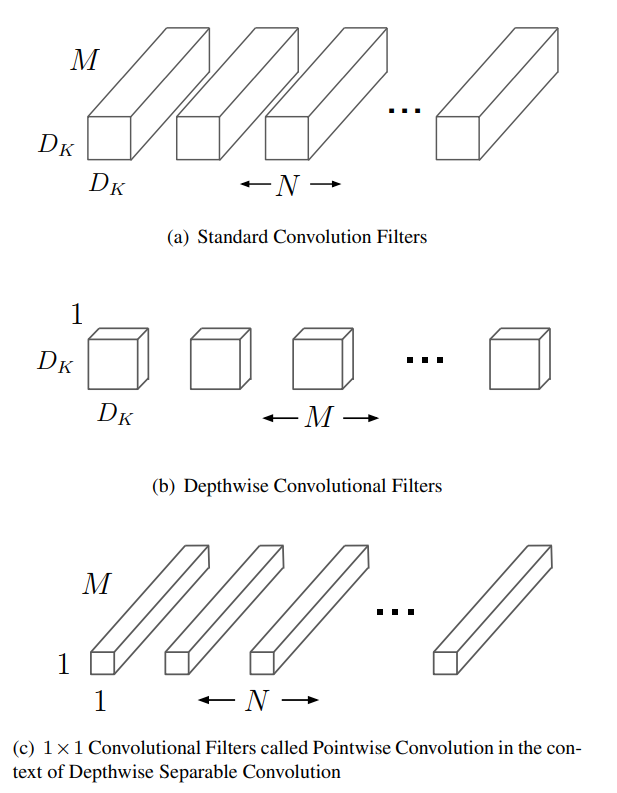
# 节省了多少
- D_K:核大小
- D_F:特征图大小(默认是正方形,F,G没有下采样)
- F:输入特征图
- G:输出特征图
- M:输入通道数
- N:输出通道数
标准卷积:
计算复杂度:
Deepwise convolution:
计算复杂度:
总计算复杂度:
两个相除结果为:
# 其他
- 用表示对通道数的缩减系数
- 用表示对输入图像分辨率的缩减系数
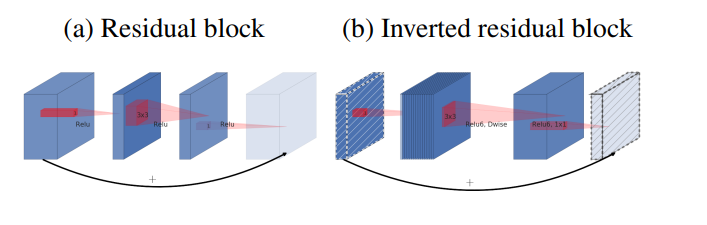
# MobileNetV2
提出了inverted bottleneck